This is issue #3 in the series Paper Pursuit where I review and summarize interesting research papers in computer science every Tuesday. You can check out the previous issues in the series here.
Original paper: Isolating Web Programs in Modern Browser Architectures
In today’s issue, we enter the exciting domain of web browsers. Browsers have been the carriers of the internet evolution, making the internet accessible to everyone from everywhere. Since I work primarily with the front end of the web at Zalando, this topic particularly interests me as it introduces a concept that is generally common today.
The paper talks about multi-process browser architecture and focuses a lot on what defines the boundaries of a web application in modern times. These boundaries define how web security and reliability evolve over time in browsers.
Introduction #
Isolating Web Programs in Modern Browser Architectures (2009) is written by two Google engineers, one of whom later worked on Chromium’s site isolation feature that put it at the forefront of multi-process browsers.
Most of the browsers during the time this paper was written were monolithic in nature, i.e. they had a single browser process that handled all of the browser’s functionality. This was natural because websites initially were only a set of web pages meant to be visited by the browser. But this was changing rapidly with the advent of client-side JavaScript applications (Gmail, Google Maps being some of the early ones) that involved much more than just loading web pages.
Another peculiarity of the web from the browser’s perspective is that they are supposed to run code from untrusted sources on the client machine, meaning if this code wasn’t well written and if the browser did not take enough precautions, it could lead to unexpected results. The monolithic architecture did not help much here, meaning one bad website could bring down the whole browser.
Yet another problem with monolithic browsers that the paper highlights is their poor security. Without isolation, it was easy for malicious actors to exploit innocent Internet users with attacks such as XSS (Cross-site scripting).
Enjoying reading? Subscribe for free to receive new posts and support my work.
The proposed solution #
The paper suggests that browsers need to behave more like an operating system and provide good process isolation for host programs that run in their environment. According to the “multi-process architecture” proposed by the paper, the browser isolates “web programs” into separate OS processes, making use of the good abstractions already exposed by the OS.
Running each web program in a separate process ensures that the browser is fault-tolerant (if a program fails, it only affects one process) and security measures can be applied to restrict data access per process. But what is a web program? Websites don’t load a single binary that runs in the browser, but it is a complex mixture of HTML, CSS, and JavaScript entities. How do we define isolation?
Finding Boundaries in web programs #
“A web program is a set of conceptually related pages and their sub-resources, as organized by a web publisher.”
Backward compatibility is a major constraint in applying internal boundaries as browsers should not break existing websites.
Origin is a strong candidate for this boundary but it is discarded as an option because websites can change their origin at runtime. A more general identifier for a web program is the site. The site is a combination of the protocol and the registry-controlled domain name.

Two more definitions are introduced - the browsing instance and the site instance. They represent internal browser representation of how users browse websites on the internet.

With these, it is now possible to define how the browser can isolate different web programs and their instances.
The new architecture #
With the isolation boundaries defined, the paper proceeds to talk about the implementation details of the new architecture, focussing on how it is implemented in Chromium. This setup is supported by three fundamental pieces in the browser.
Rendering Engine #
This is a process created for every instance of a web program and handles the parsing, rendering and execution of the program.
Browser Kernel #
This is a base process that includes all the common functionalities that are required horizontally across web programs. E.g. the browser interface, and storage.
Plugins #
A separate process handles browser plugin instances.
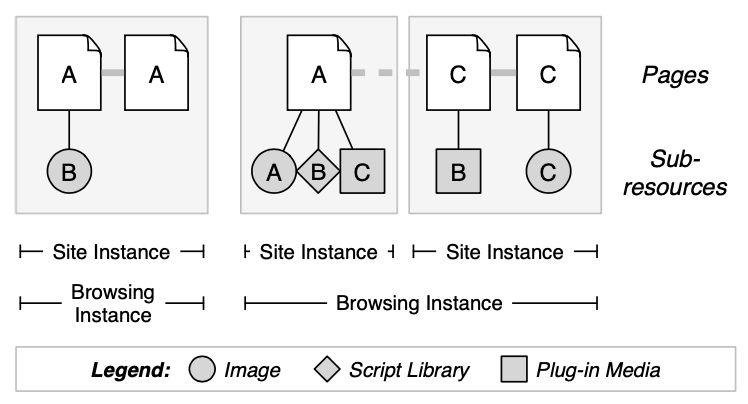
Chromium operates in a “process-per-site-instance” model by default, creating a rendering engine process for each web program instance.
Benefits and evaluation #
In the last sections, the paper discusses and analyses the benefits of the new setup. The following characteristics are provided by the multi-process browser architecture:
-
Fault Tolerance. In case of an error in the HTML renderers or JavaScript engines, only one rendering engine process is affected and the rest of the processes and web program instances remain usable.
-
Accountability. Since there the architecture operates by isolating sites and uses operating system processes to isolate resources, each process can be easily tracked and held accountable for an increase in resource usage.
-
Memory Management. This architecture makes it easy to separate and de-allocate memory per process when it has been completed.
-
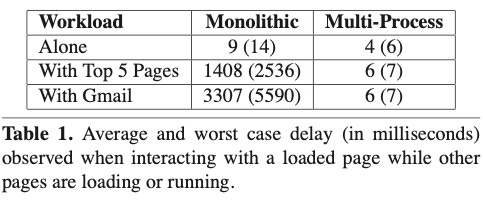
Performance. Since web program instances are on separate OS processes, they are more performant than in monolithic browsers where every website competes for resources.
-
Security. Process isolation allows better security in web programs. Chromium sandboxes rendering engine processes from accessing the filesystem and other resources.
The new architecture also provides great compatibility with existing web programs, and the paper notes that there have been no compatibility bugs reported for which the architecture was responsible.
Caveat: The overhead for multi-process #
While the multi-process architecture shines bright in several aspects, it introduces a new cost: memory overhead. Since the architecture assigns an OS process to each web program instance, a set of global cache objects have to be copied over in each of these processes. The paper found out that the average site instance footprint rises from 3.9 MB in monolithic to 10.6 MB in multi-process.
Chromium restricts the maximum number of rendering engine processes to 20, after which it reuses them for new site instances.

Takeaways and further readings #
The paper introduces the idea and motivation behind the multi-process browser architecture and shows why it is better than its monolithic counterpart by giving examples from Chromium. The architecture was pivotal in the Second Browser War as Google Chrome’s usage skyrocketed given its rich features and stability.
Mozilla’s Firefox also later moved to a multi-process architecture but took some learnings from the memory overhead issues of Chrome. Today, most browsers operate on this model, ensuring isolated failures, performance and security.
Following is a list of related readings for you.
- Inside look at modern web browser (part 1), Chrome Developers
- Google Chrome Comic, Google Chrome
- Multi-process Architecture, The Chromium Projects
- Firefox 54 Finally Supports Multithreading, May Beat Chrome on RAM Usage, ExtremeTech
Did you find this review useful? If yes, then you’d be happy to know that I write such paper reviews every Tuesday as part of the series Paper Pursuit. Subscribe to the newsletter, if you haven’t, and I’ll see you next Tuesday!


