This is issue #2 in the series Paper Pursuit where I review and summarize interesting research papers in computer science every Tuesday. You can check out the previous issues in the series here.
Original paper: End-To-End Arguments in System Design
Introduction #
This paper discusses where functionality should be placed in a distributed system consisting of several layers of software. It presents a principle called the end-to-end argument, which states that common functionality provided at lower levels of a system is usually redundant due to the high cost of providing it.
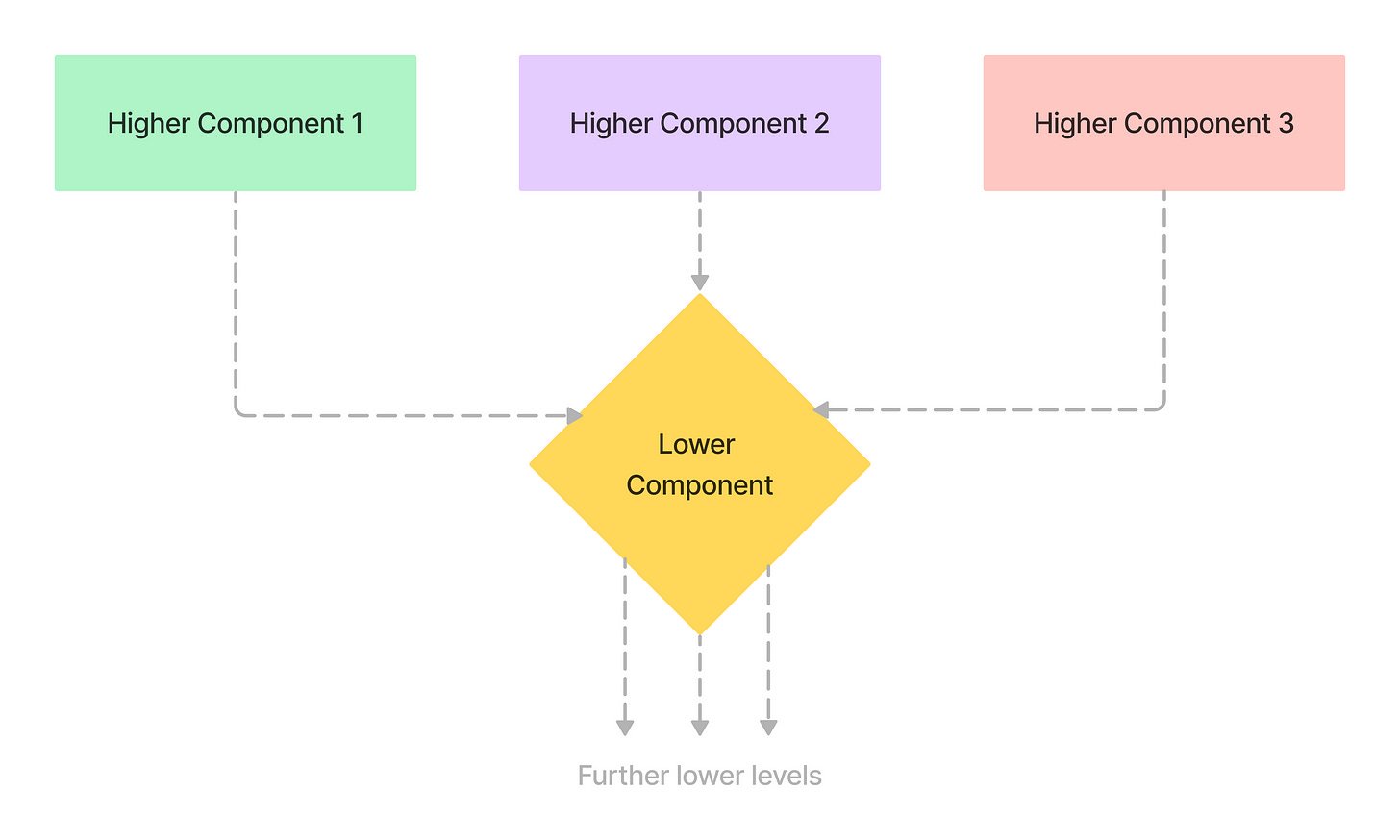
I find this paper relatable not only to distributed systems but also to modern-day software. Today, a lot of software is built modularly in the form of frameworks, libraries, plugins, and platforms that abstract underlying functionality. The end-to-end argument is equally applicable to developers building such abstractions.
An example of a careful file transfer #
The paper takes the example of careful file transfer to support the argument. Let’s consider an example of transferring a file from machine A to machine B, both of which are connected over a network. The flow of data would look like this:
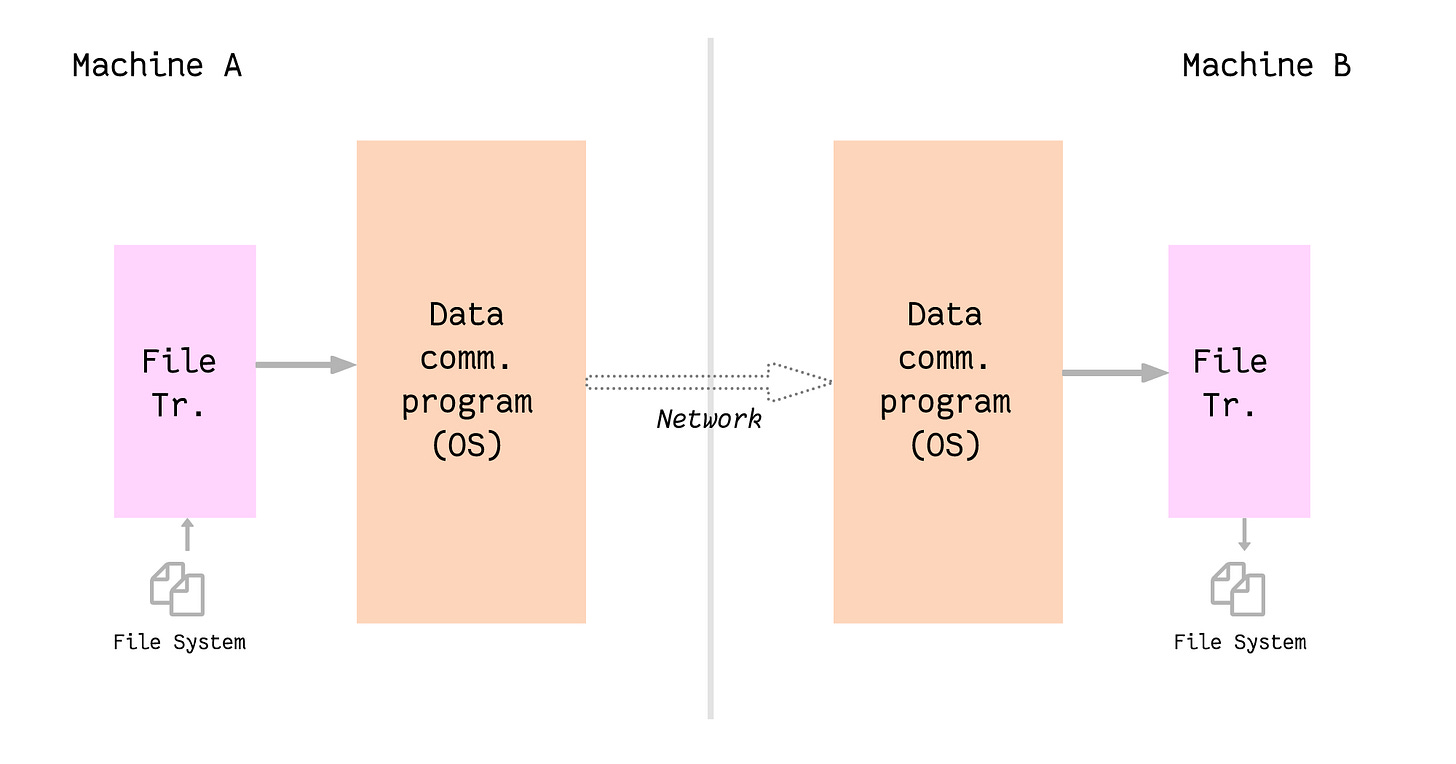
Steps involved in the file transfer include:
- The file transfer program reads the file from the file system in machine A.
- It then passes the file data to the data communication program to be sent over the network. The file transfer program splits the file into chunks.
- The data communication program converts these chunks into data packets and sends them over the network using a suitable protocol.
- The data comm. program on machine B receives these packets and extracts the file data from them and passes them over to the file transfer program.
- The file transfer program on machine B now sees the file chunks and it saves them as a file to the file system.
Things can go wrong at various points in this flow, e.g. the file transfer program or the communication program might make a mistake while transferring the data. Or some data packets might get dropped while being sent over the network.
To ensure end-to-end correctness in the process above, one can debate if the correctness logic should be implemented in the data communication layer which sends and receives data packets between computers, or whether it should sit inside the file transfer application which operates on file chunks.
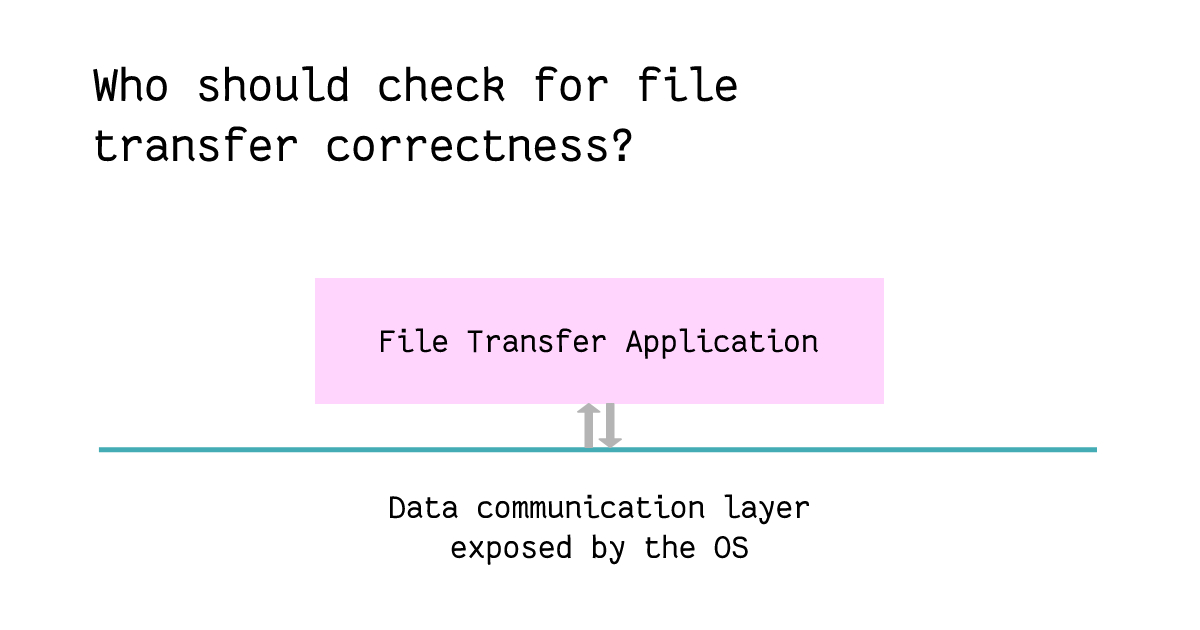
Correctness here means that the file sent from the source computer was received correctly by the receiver.
At the file transfer application level, one could use checksums to verify that the received data exactly matches the sent data, and if not, then retry.
At the data communication level, checksums cannot be applied since the layer can only look at the file in terms of “data packets”, hence one would have to apply the logic at a packet/chunk level. The correctness is verified by checking if the packets sent were actually received.
The paper then states that implementing this logic in the data communication layer has the following two major disadvantages:
- The data communication layer is also used by applications other than the file transfer program. Adding the correctness logic per data packet would lead to overhead and impact the performance of the entire data communication layer, thus affecting other applications using it.
- The data communication layer may not have enough information as compared to higher levels. It may not be able to use the sophisticated logic that can be implemented at the file transfer application level. E.g. the file transfer application can check precisely if the file chunks arrive correctly.
This example points to an important conclusion - checking correctness at the lower levels is redundant as it will have to be verified at the higher level anyway, and may even negatively affect the overall system as other users of the low level may not require the feature.
This seems like an obvious statement, but it is a crucial principle to note while designing systems with multiple layers. This is evident in today’s microservice ecosystem where a service can have numerous chained dependencies.
Other examples #
The paper provides a few other examples where the argument holds true. This principle formed the core of modern-day Internet infrastructure which emphasizes keeping the network core simple and implementing specific functionality on the edge.
For example, if you compare today’s network layers, the Transport Control Protocol (TCP) at the transport layer implements several correctness and congestion control logic rather than keeping it at the network layer (Internet Protocol - IP). TCP implements the TCP handshake to ensure reliability in the connection, the IP layer ensures a best-effort connection and does not implement reliability logic.
This is a great advantage because if this logic existed in the IP layer, we would not have the User Datagram Protocol (UDP) - which gives away reliability and focuses on faster data transfer, crucial for applications like video calling and live streaming.
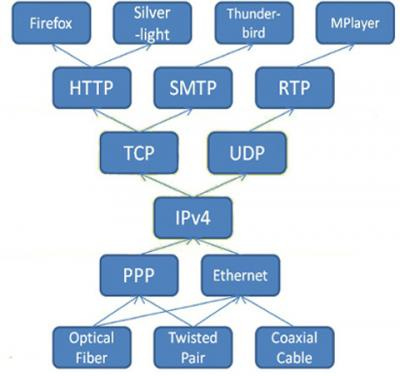
This nature is often called the hourglass shape of the Internet infrastructure. There are more protocols toward the edges of the network than at the centre, and this is in line with the end-to-end argument presented by this paper.
End-to-end arguments in software #
I am tempted to apply this argument to large-scale software as well. If you work with software, there is a high chance that you have worked with a framework, e.g. React on the front end, Express.js, Spring Boot, Next etc. on the back end. All of these frameworks provide additional features for specific use cases that the core language does not.
Additionally, specific libraries can use the framework APIs to provide even more targeted features, e.g. component libraries like antd provide advanced UI components that use React APIs to provide specific features.
Is this similar to the end-to-end principle?
It looks familiar. It would be wrong to fit this into the end-to-end model, but what helps is to draw learnings from the principle. If you work on a framework or a language, it is important to decide what features should be provided as part of your core offering. Too specific features might not be useful as they would have to be replicated at higher levels anyway.
Takeaways and further readings #
The paper suggests that placing functionality at lower levels in a system may not be the most effective solution and rather it should be placed at the top levels to keep the lower levels simple. This works for well for the internet infrastructure and systems but should be taken with a pinch of salt and the principle should be verified on a case-by-case basis.
A paper by Microsoft in 19981 argued the application of this principle for battery energy management in portable computers while discussing where this capability should be placed in the system.
What do you think about this principle? Reply with your comments on this email. I’ll see you next week again, with another interesting paper!

Software Strategies for Portable Computer Energy Management, Jacob R. Lorch, Alan Jay Smith, February 24, 1998


