I feel like today's observability systems have grown bigger and bigger with a self-inflicted upper limit. Yes there are multitudes of vendors to choose from and thankfully great standardization with OpenTelemetry, but I think we need more. And I'm not talking about the vendor platforms but rather about the general observability method.
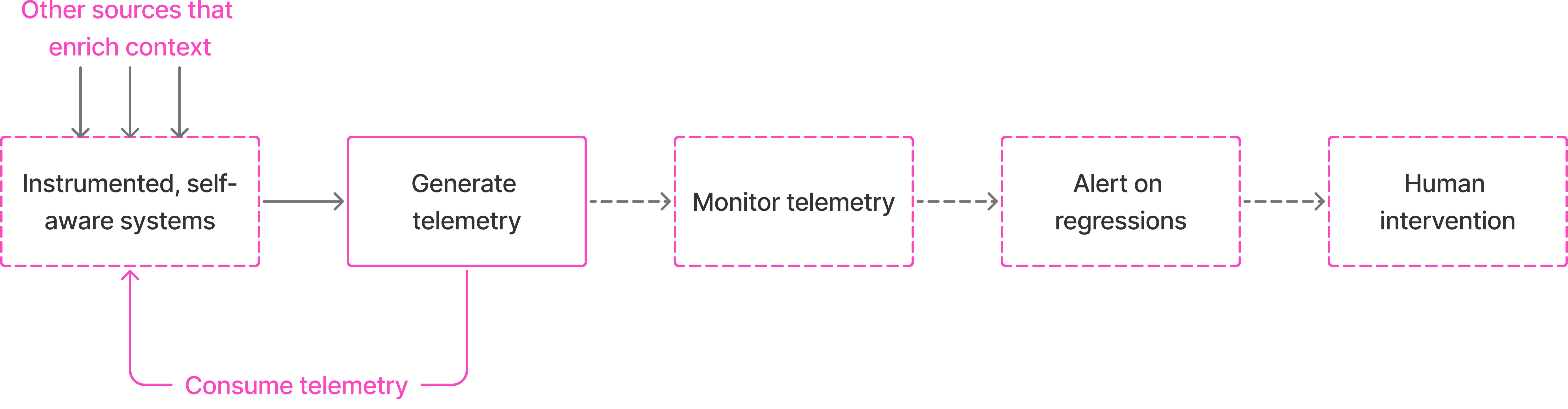
Today, a typical flow of ensuring good system health looks like:

With increasing states of the system to monitor, we either increase the level of human intervention or depend on abstractions like Kubernetes or underlying systems that orchestrate for you, considering your system as a black box. These are great already and handle a lot of cases for system owners by managing availability of resources and maintaining a state of equilibrium as defined by the owners.
Yet, the fact that orchestration layers look at systems as a black box leads to the loss of rich context a system owner has about what goes on inside the system, and a potential opportunity to use this context to implement some mechanisms.
A common practice is to introduce human intervention wherever the problem is too context-heavy and abstractions cannot respond to such situations. E.g. if you own a service that renders HTML pages on the server (consider a typical React SSR) and the system suffers some issue and the latency to render a page increases drastically. You scale horizontally but hit a limit. The orchestration layer could only do so much. But wait, since you own the service you know exactly what happens when rendering a page. So you decide to use a config flag to turn off a chunk of expensive calculation and instead let it render on the client side. You toggle this flag and the service comes back to normal health!
The response in this example required deeper system context. And today, the practice is to use playbooks whenever an alert fires and this playbook is executed by a human. Why cannot we automate this?
There has been past research into self-adapting software and the base of this research is that software can achieve the same output (with different quality) in more that one way. In the example, the output was a visible and interactive HTML page for the user and the system could produce it in more than one way. The idea is to make the system aware of these ways and let it automatically choose one depending on external factors.
What I'm trying to envision is that observability signals should not only alert humans, but also be useful to write self-adapting logic. Imagine having a dynamic configuration store in your service that is aware of current operational metrics:
registerConfig("USE_CLIENT_SIDE_RENDERING", (ctx) => {
if(ctx.operations["request"].latency_p99 > 1500) {
return true;
}
return false;
});This is telemetry data as code. I believe this would be a game-changer. Making your system aware of what's happening can enable you to write context-aware adapting code.
Another example I can think of is using historical context. I am working on a test automation engine where I am introducing a historical context-aware logic. Test flakiness is a big problem with end-to-end tests and one idea to self-adapt your test suite is to check historical performance of your tests. If a test has been behaving oddly in the past, you can decide to quarantine it and not execute it at all.
const check = (id: string) => {
const history = getTestHistory(id);
test.skip(history.shouldSkip);
}
test("Test product detail page", ({ page }) => {
const id = testMap["Test product detail page"];
check(id);
// test logic
});The getTestHistory() function would depend on the past reporting data and some analytics performed over it.
Another example where adaptability is already used is circuit breakers. Most circuit breakers are based on client-side timeouts and are not really aware of external state, but still they are a good example of how systems adapt to situations. A circuit breaker opens when it sees that a request to an upstream service has taken longer than expected and instead of affecting the operation or impacting upstream, it is better to not make the request.
Recently, with generative AI, this topic is becoming more interesting. With enough context, AI can potentially act as a self-healing agent by committing code changes. This was recently shared by Vercel in their post. Previously, a LinkedIn user also implemented a self-healing Playwright agent which would fix your tests in case of failures. I'm still not very sure if this is the right path ahead and would depend on deterministic changes using config values, but it is an interesting evolving space.
In the future, we'll probably have systems that work as follows: