I have been trying my hand at systems programming by building small projects related to low-level systems in C++. It also helps me brush up my C++ skills, often useful for my masters programs and to gain a fresh perspective at programming as compared to my usual work in TypeScript. Recently, I decided to write a minimal version of the event loop, a popular construct in asynchronous programming and a foundation of any JavaScript runtime.
Asynchronous programming and events #
Async programming models a system around events for concurrency, unlike the multi-threaded programming paradigm which models it around dividing work. In async programming, execution of a code block is stalled if it accesses a certain blocking component (usually I/O, e.g. network or file system) and the runtime continues to execute other tasks in the meantime. Using threads, one would achieve concurrency by ensuring there is a thread per context (e.g. a thread per incoming request for a server) and hence two contexts can be executed concurrently.
A place where async programming shines is that it can be implemented on a single thread and it provides a great API for the programmer to work with. You do not think about synchronization with mutex locks or race conditions, but rather model your program with a single thread of execution in mind. Under the hood though, the runtime may decide to use multiple threads to achieve concurrency. In order to increase concurrency, you can use multiple instances of the runtime. (This is at times costlier than threads, but depends on the use case)
Events in asynchronous programming are usually handled and coordinated using an event loop. There is no such primitive as an "event" in hardware, i.e. to know that something has happened/changed, the program has to check explicitly, a process called polling where the program polls for a status/value to know if it has changed. And this is what the event loop implements to give a notion of events and notifications. Talking specifically about Node.js, libuv provides the capability of async I/O to the runtime - it provides APIs to work with various I/O operations like network, file system and DNS.
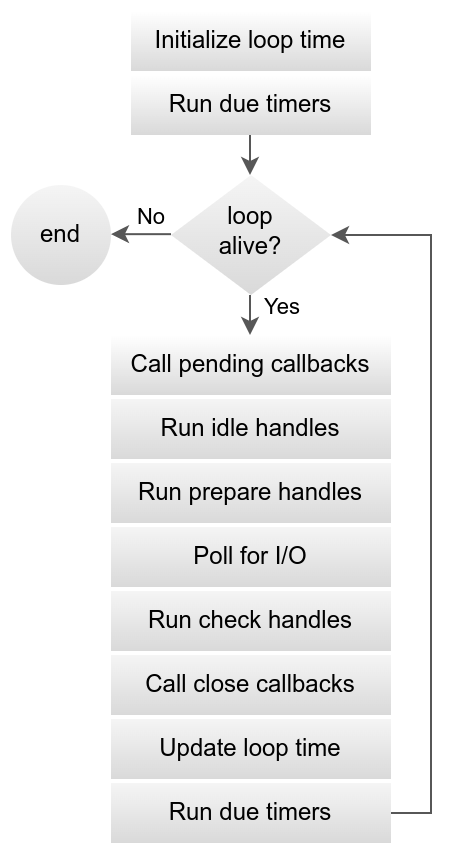
Essentially, an event loop is a long-running loop that does a bunch of things in one iteration. To keep it simple, in each iteration it executes any new tasks, polls for any pending events and runs any due timers before going back to the next iteration. The polling happens in the iteration and hence has to be configured with a timeout so that the loop can proceed with other things and not get blocked on the I/O events. For my event loop, I took a file system operation as the I/O event I would be waiting for. Imaging running the following Node.js code (taken directly from Node.js docs):
const fs = require('node:fs');
console.log("Hello");
const content = 'Some content!';
fs.writeFile('/Users/joe/test.txt', content, err => {
if (err) {
console.error(err);
} else {
console.log("File written!");
}
});
console.log("Write requested");You would expect the program to log this:
Hello
Write requested
File written!I'll implement the loop that will run in a way similar to the above code.
Let's write an event loop #
My event loop has the following structure:
class EventLoop
{
private:
std::queue<Task *> queue; // Task queue
int kq; // (will describe this below)
std::thread loopThread; // The main loop thread
std::mutex queueMutex; // Mutex for the task queue
void goAroundTheLoop(); // The loop method
public:
EventLoop(); // Constructor
void schedule(Task *task); // To schedule a new task
void wait(); // To join on the loop thread
};The most important parts are the queue which stores the requested tasks to be executed and the loopThread which runs the event loop logic located in goAroundTheLoop(). A Task is a simple class that represents some work to do - it holds a reference to a function which contains the logic of the task.
class Task
{
private:
std::function<void()> (*fn)(int);
std::string name;
public:
Task(std::string name, std::function<void()> (*_fn)(int));
std::function<void()> execute(int kq);
};The class is implemented as follows:
Task::Task(std::string name, std::function<void()> (*_fn)(int))
{
name = name;
fn = _fn;
}
std::function<void()> Task::execute(int kq)
{
return fn(kq);
}When there is new work, the runtime calls schedule():
void EventLoop::schedule(Task *task)
{
std::lock_guard<std::mutex> lock(queueMutex);
queue.push(task);
}And to simply execute this task, goAroundTheLoop() pulls new tasks as they arrive.
void EventLoop::goAroundTheLoop()
{
std::function<void()> callback;
while (1)
{
// std::cout << "Going around the loop" << std::endl;
{
std::lock_guard<std::mutex> lock(queueMutex);
if (queue.size() > 0)
{
Task *task = queue.front();
queue.pop();
callback = task->execute(kq);
}
}
// rest hidden for now
}
}Polling for I/O events #
The above implementation will be able to run synchronous tasks but for tasks involving I/O operations we need to include a way to poll them while not blocking the event loop. The goal is to let the while loop run (so that it can pull new tasks and execute them) even when one of the tasks has an I/O operation.
Polling for I/O events can be implemented using certain system calls and they differ for each platform (linux, macOS, Windows). The libuv docs enlist what it uses for each platform:
Full-featured event loop backed by epoll, kqueue, IOCP, event ports.
Specifically, kqueue is a system call that lets you poll for events on macOS. The way it works is simple:
- You create a "kqueue" where you will get notified of events
- You create an event description for what you want to get notified for (e.g. file write, file read etc.)
- You wait for the event to happen by reading the queue
- Here is where polling comes in. The
keventAPI allows you to set a timeout for a read. So you can simulate polling by setting a timeout and then letting the event loop check on the queue during each iteration.
- Here is where polling comes in. The
Using kqueue, I extended the goAroundTheLoop() method:
void EventLoop::goAroundTheLoop()
{
std::function<void()> callback;
while (1)
{
// std::cout << "Going around the loop" << std::endl;
{
std::lock_guard<std::mutex> lock(queueMutex);
if (queue.size() > 0)
{
Task *task = queue.front();
queue.pop();
callback = task->execute(kq);
}
}
struct kevent tevent;
struct timespec ts;
ts.tv_sec = 0;
ts.tv_nsec = 1e7;
int ret = kevent(kq, NULL, 0, &tevent, 1, &ts);
if (ret > 0)
{
std::cout << "Event: written to file" << std::endl;
callback();
}
}
}And example task using the kqueue looks as follows:
std::function<void()> readFileWrite(int kq)
{
// ################ Attaching a file change event ################
struct kevent event;
int ret, fd;
fd = open("file", O_RDONLY);
EV_SET(&event, fd, EVFILT_VNODE, EV_ADD | EV_CLEAR, NOTE_WRITE,
0, NULL);
ret = kevent(kq, &event, 1, NULL, 0, NULL);
if (ret == -1)
{
std::cerr << "Failed to attach kevent" << std::endl;
std::exit(1);
}
// ################ ############################# ################
// ############### Return the callback as a lambda ###############
return []
{
std::cout << "Finally, something written to the file!" << std::endl;
};
// ############### ############################### ###############
}The way async events work here:
- A
kqueueis created whenEventLoopis constructed. - The loop pulls a task from the event queue.
- The task is executed by calling
task.execute()and the descriptor of thekqueue(kq) is passed as an argument. - Inside the task, a
keventis created and appropriate properties are set to denote the type of event we want to be notified for. This event is then attached to the queue usingkevent(). - To do some work after the file has changed, the logic to be run is returned from the function as a lambda.
- In
goAroundTheLoop(), the callback is stored in a variable. Thekqueueis polled usingint ret = kevent(kq, NULL, 0, &tevent, 1, &ts);wheretsis atimespec, denoting the timeout value for the polling. After the time has passed, the function will return with a negative value.- In case an event arrives (a change is made to the file), the return value is positive and the stored callback is executed.
- And the loop goes around again.
That's how we have an event loop! The iteration logic can be extended to add things like timers, other types of events like network I/O. Implementing the loop by hand gives me an added understanding of the runtime I use daily at work. To quote Feynman here:
What I cannot create, I do not understand.
-- Richard P. Feynman
Full code is hosted here if you're interested: https://github.com/mohitk05/systems-programming-basics/blob/main/event_loop.cpp
I also did a video on this:


